728x90
백준 1193번 문제: 분수찾기
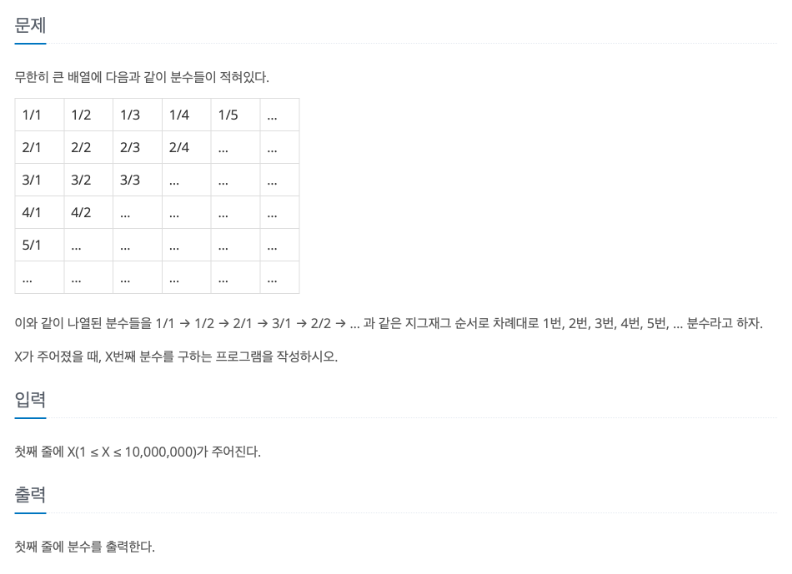
문제 설명
- 양의 정수를 순서대로 분수에 배치하여 다음과 같은 규칙을 따릅니다:
- 1/1 → 1/2 → 2/1 → 3/1 → 2/2 → 1/3 → ...
- 주어진 정수 X에 대해, 번째에 해당하는 분수를 구해야 합니다.
문제 해결 전략
- 규칙 분석:
- 분수는 대각선 그룹으로 나뉩니다.
- 그룹 1: 1/1 (1개)
- 그룹 2: 1/2,2/1 (2개)
- 그룹 3: 3/1,2/2,1/3 (3개)
- 그룹 : n개의 분수로 이루어짐.
- 그룹 번호 찾기:
- X번째 분수는 어느 대각선 그룹에 속하는지 알아야 합니다.
- 그룹 n까지의 합은 삼각수: sum=1+2+3+⋯+n=n(n+1) / 2
- 가 포함되는 그룹 n은 n(n+1) / 2 ≥ X일 때 찾을 수 있습니다.
- 해당 그룹에서의 위치 계산:
- 그룹 의 시작 번호는 (n−1)n / 2 + 1
- 는 그룹의 시작 번호로부터 몇 번째에 위치하는지 계산합니다.
- 분수 방향:
- 그룹 번호가 홀수: 분자 감소, 분모 증가.
- 그룹 번호가 짝수: 분자 증가, 분모 감소.
코드 구현
X = int(input()) # 입력값 X
# 그룹 번호 찾기
group = 1
while X > group * (group + 1) // 2:
group += 1
# 해당 그룹에서의 위치
start_of_group = (group - 1) * group // 2 + 1
position_in_group = X - start_of_group
# 분수 계산
if group % 2 == 0: # 짝수 그룹
numerator = 1 + position_in_group
denominator = group - position_in_group
else: # 홀수 그룹
numerator = group - position_in_group
denominator = 1 + position_in_group
print(f"{numerator}/{denominator}")코드 설명
- 그룹 번호 찾기:
- 그룹 번호는 n(n+1) / 2 ≥ X 조건을 만족할 때까지 증가시킵니다.
- 그룹 시작 번호:
- 그룹 n의 시작 번호는 (n−1)n / 2 +1 로 계산합니다.
- 그룹 내 위치:
- 가 그룹에서 몇 번째인지 계산:
position_in_group = X - start_of_group
- 가 그룹에서 몇 번째인지 계산:
- 분수 계산:
- 짝수 그룹이면 분자가 증가하고 분모가 감소.
- 홀수 그룹이면 분자가 감소하고 분모가 증가.
입출력 예시
입력:
14
출력:
2/4
풀이 과정:
- X = 14 → 그룹 5에 속함 (5(5+1) / 2 = 15)
- 그룹 5의 시작 번호: (5−1)5 / 2 + 1 = 11
- 그룹 내 위치: 14 − 11 = 3
- 그룹 5는 홀수 그룹 → 분자 = 5−3=2, 분모=1+3=4
728x90
반응형
'console.log("What ? " + Cord); > 코딩테스트' 카테고리의 다른 글
| [백준] 1018번 - 체스판 다시 칠하기 파이썬 (Python) (1) | 2024.11.29 |
|---|---|
| [백준] 24262번 - 알고리즘의 수행 시간 1 파이썬 (Python) (0) | 2024.11.27 |
| [백준] 2869번 - 달팽이는 올라가고 싶다 파이썬(Python) (0) | 2024.11.26 |
| [백준] 1316번 - 그룹 단어 체커 파이썬(Python) (0) | 2024.11.26 |
| [백준] 1157번 BAEKJOON 단어 공부 파이썬(Python) (0) | 2024.11.25 |