N = int(input()) # 입력값
# 위쪽 피라미드
for i in range(1, N + 1):
print(" " * (N - i) + "*" * (2 * i - 1))
# 아래쪽 피라미드
for i in range(N - 1, 0, -1):
print(" " * (N - i) + "*" * (2 * i - 1))
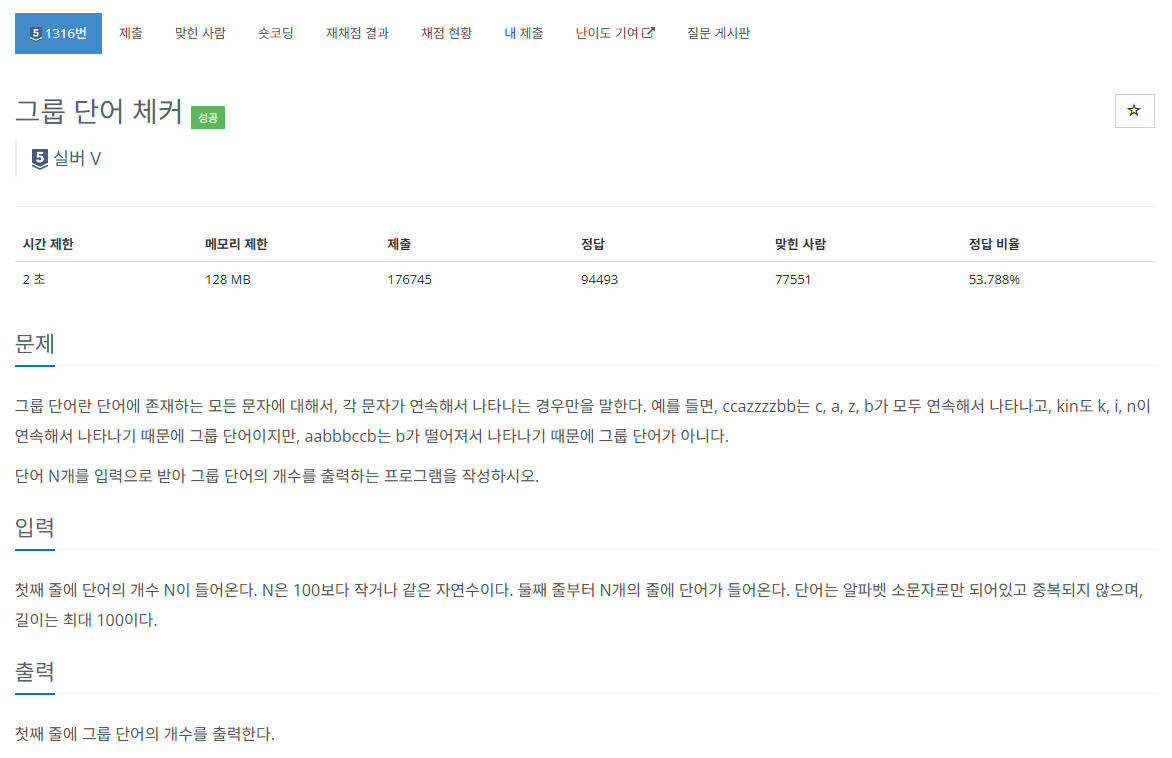
def is_group_word(word):
seen = set() # 등장한 문자를 저장할 집합
prev_char = None # 이전 문자를 저장
for char in word:
if char != prev_char: # 이전 문자와 다를 때
if char in seen: # 이미 등장했던 문자면 그룹 단어 아님
return False
seen.add(char) # 새로운 문자를 추가
prev_char = char # 이전 문자를 갱신
return True # 모든 문자가 조건을 만족하면 그룹 단어
# 입력 처리
n = int(input()) # 단어 개수
count = 0
for _ in range(n):
word = input()
if is_group_word(word): # 그룹 단어라면 카운트 증가
count += 1
print(count)
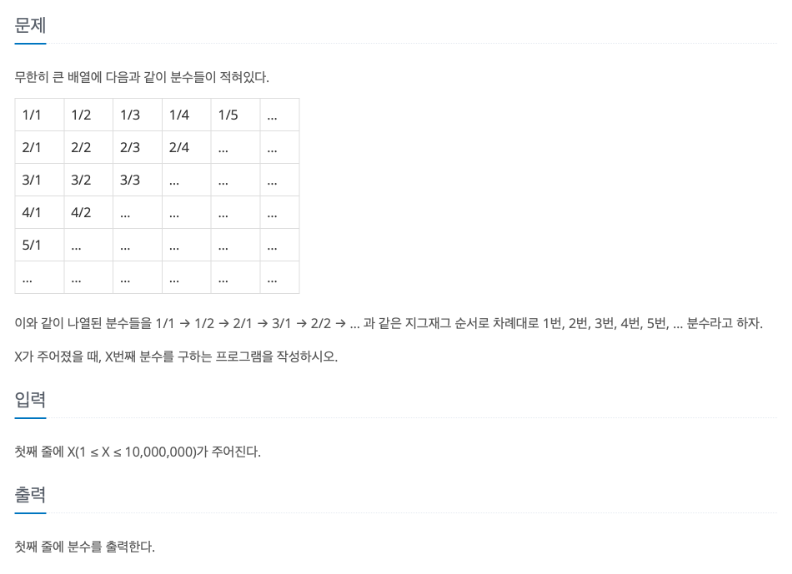
X = int(input()) # 입력값 X
# 그룹 번호 찾기
group = 1
while X > group * (group + 1) // 2:
group += 1
# 해당 그룹에서의 위치
start_of_group = (group - 1) * group // 2 + 1
position_in_group = X - start_of_group
# 분수 계산
if group % 2 == 0: # 짝수 그룹
numerator = 1 + position_in_group
denominator = group - position_in_group
else: # 홀수 그룹
numerator = group - position_in_group
denominator = 1 + position_in_group
print(f"{numerator}/{denominator}")
알파벳 대소문자로 된 단어가 주어지면, 이 단어에서 가장 많이 사용된 알파벳이 무엇인지 알아내는 프로그램을 작성하시오. 단, 대문자와 소문자를 구분하지 않는다.
입력
첫째 줄에 알파벳 대소문자로 이루어진 단어가 주어진다. 주어지는 단어의 길이는 1,000,000을 넘지 않는다.
출력
첫째 줄에 이 단어에서 가장 많이 사용된 알파벳을 대문자로 출력한다. 단, 가장 많이 사용된 알파벳이 여러 개 존재하는 경우에는 ?를 출력한다.
[ 테스트 코드 ]
x = input()
xList = list(x.upper())
print(xList)
# 주어진 리스트
letters = ['M', 'I', 'S', 'S', 'I', 'S', 'S', 'I', 'P', 'I']
# 빈 딕셔너리로 개수 세기
counts = {}
for letter in letters:
counts[letter] = counts.get(letter, 0) + 1
# 중복된 값 추출
duplicates = {key: value for key, value in counts.items() if value > 1}
print(duplicates) # 출력: {'I': 4, 'S': 4}
data = input().upper()
max_char = max(set(data), key=data.count)
max_count = data.count(max_char)
if sum(1 for char in set(data) if data.count(char) == max_count) > 1:
print('?')
else:
print(max_char)
여기서 중요했던 요점은 문자를 대문자로 변형하고 중복 값을 체크 하는 것이다.
[ 결과 코드 ]
data = input().upper()
max_char = max(set(data), key=data.count)
max_count = data.count(max_char)
if sum(1 for char in set(data) if data.count(char) == max_count) > 1:
print('?')
else:
print(max_char)
웹 크롤링은 인터넷 상의 데이터를 자동으로 수집하고 분석하는 작업으로, 데이터 분석, 연구, 비즈니스 인사이트 등에 활용될 수 있습니다.
특히 Python은 다양한 라이브러리와 커뮤니티의 지원 덕분에 웹 크롤링을 수행하기에 최적의 언어로 꼽힙니다.
Python을 사용해 웹 크롤링을 시작하는 방법과 핵심 기술을 다루어보겠습니다.
1. 웹 크롤링의 기본 개념
웹 크롤링이란?
웹 크롤링은 프로그램이 웹사이트를 방문해 특정 정보를 추출하는 과정을 의미합니다.
흔히 사용되는 사례로는 상품 가격 비교, 뉴스 데이터 수집, 소셜 미디어 분석 등이 있습니다.
웹 크롤링의 작동 원리
웹 크롤러는 다음과 같은 과정을 따릅니다:
HTTP 요청 보내기: URL을 통해 서버에 요청을 보냅니다.
HTML 응답 받기: 서버로부터 HTML 문서를 수신합니다.
데이터 파싱: HTML 문서에서 원하는 데이터를 추출합니다.
저장: 추출한 데이터를 CSV, 데이터베이스 등에 저장합니다.
2. Python의 주요 웹 크롤링 도구
1) requests
requests는 HTTP 요청을 보내기 위한 라이브러리입니다. 웹페이지에 접속하여 HTML 문서를 가져오는 데 사용됩니다.
import requests
url = 'https://example.com'
response = requests.get(url)
if response.status_code == 200:
print(response.text) # HTML 내용 출력
2) BeautifulSoup
BeautifulSoup는 HTML 파싱을 돕는 라이브러리로, 특정 데이터 추출에 유용합니다.
from bs4 import BeautifulSoup
html = "<html><body><h1>안녕하세요</h1></body></html>"
soup = BeautifulSoup(html, 'html.parser')
print(soup.h1.text) # "안녕하세요" 출력
3) Selenium
동적인 웹사이트를 크롤링할 때 사용되는 브라우저 자동화 도구입니다. 자바스크립트를 통해 생성된 데이터를 처리할 수 있습니다.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://example.com')
print(driver.page_source) # 렌더링된 HTML
driver.quit()
3. 간단한 웹 크롤링 예제
예제: 네이버 뉴스 헤드라인 가져오기
import requests
from bs4 import BeautifulSoup
url = 'https://news.naver.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.select('.hdline_article_tit a') # 네이버 뉴스의 헤드라인 CSS 클래스
for idx, headline in enumerate(headlines, 1):
print(f"{idx}. {headline.text.strip()}")